Public datasets are a dime a dozen.
You could always collect your own data, albeit this is no easy task. Would we implement surveys? How would we pick the right questions? Could we auto-collect it from some handy dandy system that’s already automated anyway? Stream it right into our database? Remember the last time something was as easy as it seemed? Me neither.

I struggle with the idea of just yoinking something from the Internet and it being totally fine. I’m sure a lot of datasets are safe, well maintained, and totally legit. But you never know know unless you get it straight from the source whether a set of data has been tampered with, be it intentionally or not.
Public datasets can also be difficult to use when you are brand new and self-taught. How do you clean data? How do you know if you have to clean the data? How do you import data? What’s a relative path? What’s an absolute path? What’s a path?? What is data?
Meanwhile, with the abundance in general data availability, you are bound to select something familiar to you. Something you already have opinions on.
This is called, bias. And bias is bad. If you decide what the data is telling you before it says anything at all, that’s bad. Not that you would do such a thing on purpose. But that’s bias for ya. Bias would also exist in a tampered-with dataset (intentional or not).
Indeed, bias is not limited to what your own opinions may or may not introduce your model. Wikipedia has a list of all the types of bias out there. Data Scientist Dr. William Goodrum has a very short article with a little more detail.
By the way, it’s possible to create your own dataset with essentially no bias. “Random” data. Monte Carlo simulation. And you won’t even have to clean it. Honest.

Monte Carlo data is the best data on which to practice one’s python skills (it’s also a great risk analysis tool). Using a dictionary and a built-in python package called random, we will generate random, clean, and unbiased data. But first:
Why is random data not biased?
Take a 12-sided di. When you roll it once, you get a 9. You roll it again.
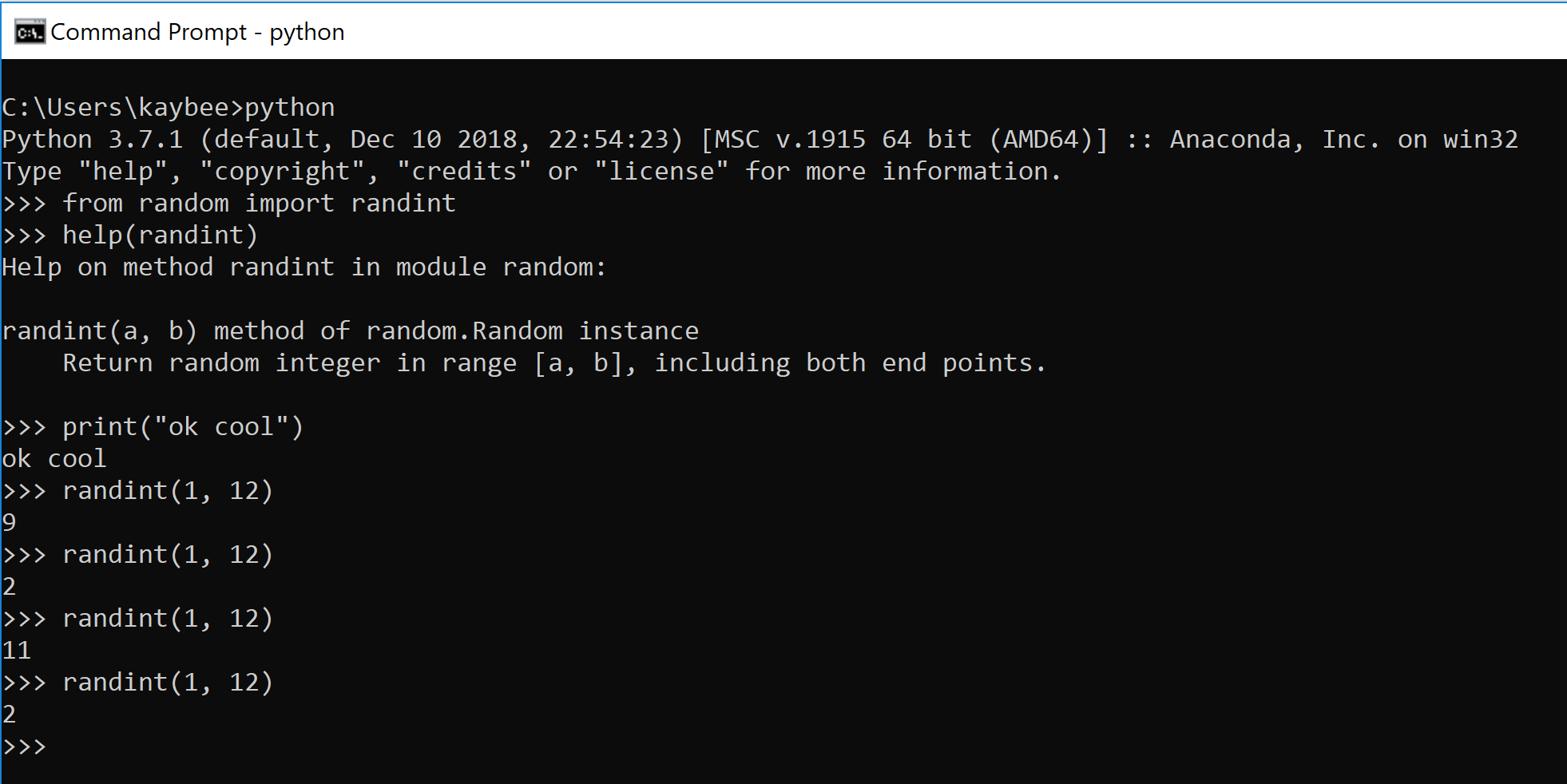
>>>randint(1, 12)You may get a 2, an 11, and another 2. But what if I rolled the di 1000 times? I know, why would I do that? It would take forever. Computers are good at doing the same thing over and over real fast. Let’s have the computer do it.
We’ll talk to the computer with python.
In a Jupyter notebook.
Jupyter Notebook makes more sense than an IDE (or a combo of Notepad++ and GitBash) or the command line because it is more iterative-friendly. It has these blocks, or cells that you can either run immediately, or ignore. Jupyter Notebooks run in-memory. These attributes enable fast and flexible experimentation.
All the code for this exercise can be found here under the folder MonteCarlo. This exercise is called Basic Random Data Simulation.
The dictionary monte_carlo will store our data. The keys will coordinate with each side of the 12-sided di. So there will be 12 keys (1, 2, 3, …, 12).
The values will coordinate to how many times that number was “rolled.”

I used a for loop to generate 1000 rolls. Inside the for loop, which I told to run 1000 times, I roll the di. Say it’s an 8.

If 8 is a key in the dictionary {}, then increment 8’s value by 1. Otherwise, insert 8 as a new key and set the value equal to 1.
Note that in the first few rolls, the else statement will definitely be executed to initialized all the values, but by the time we reach the end of the 1000 runs, all 12 keys will likely exist. At some point, the else statement will be ignored for the remainder of the loop. A while loop would have worked, too.
Let’s try that.
Also, since the keys are known prior to performing the loop, let’s try initializing them before the loop with a dictionary comprehension. A dictionary comprehension is a way of creating a dictionary without hardcoding stuff. They are useful for creating dictionaries with variable keys and/or values, as well as for creating really, really big dictionaries that would be cumbersome to code otherwise (but still follow some pattern, such as start from 1, end at 12, increment by 1, and initialize all values with 0).
This sightly different method avoids that extra if/else computation. Just like walking, the extra steps come at a cost. And less important, but the else statement is only useful in the beginning of the loop. It’s sad to see wasted potential, you know?
First lesson of while loops is don't let it run forever. Don’t get stuck in forever.
The below code is going to run forever. The i never increments, so i is always zero and we never exit the loop. A faster way of knowing the loop is stuck is the asterisk [*].

This indicates the Jupyter cell is running. More than a few seconds is probably too long. Luckily, Jupyter has a stop button for that (although in theory the loop would run forever, it would actually stop once Jupyter, which means your machine if running on localhost, ran out of memory).

Anyway, here’s some code to generate 1000 rolls, no infinite loop, no funny business:

We can get fancy with printing the dictionary, because why not?
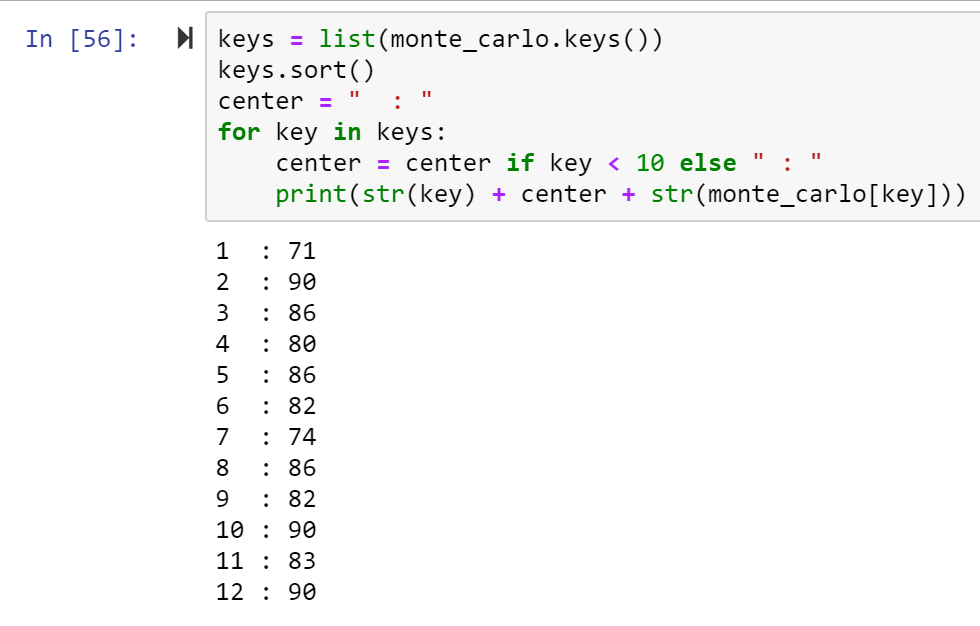
Even with the data printed out all nice it’s still kind of hard to see the distribution. We can easily see like how many 2’s we got this time, but what about how many 2’s compared to how many 3’s? How does the data look relative to one another?
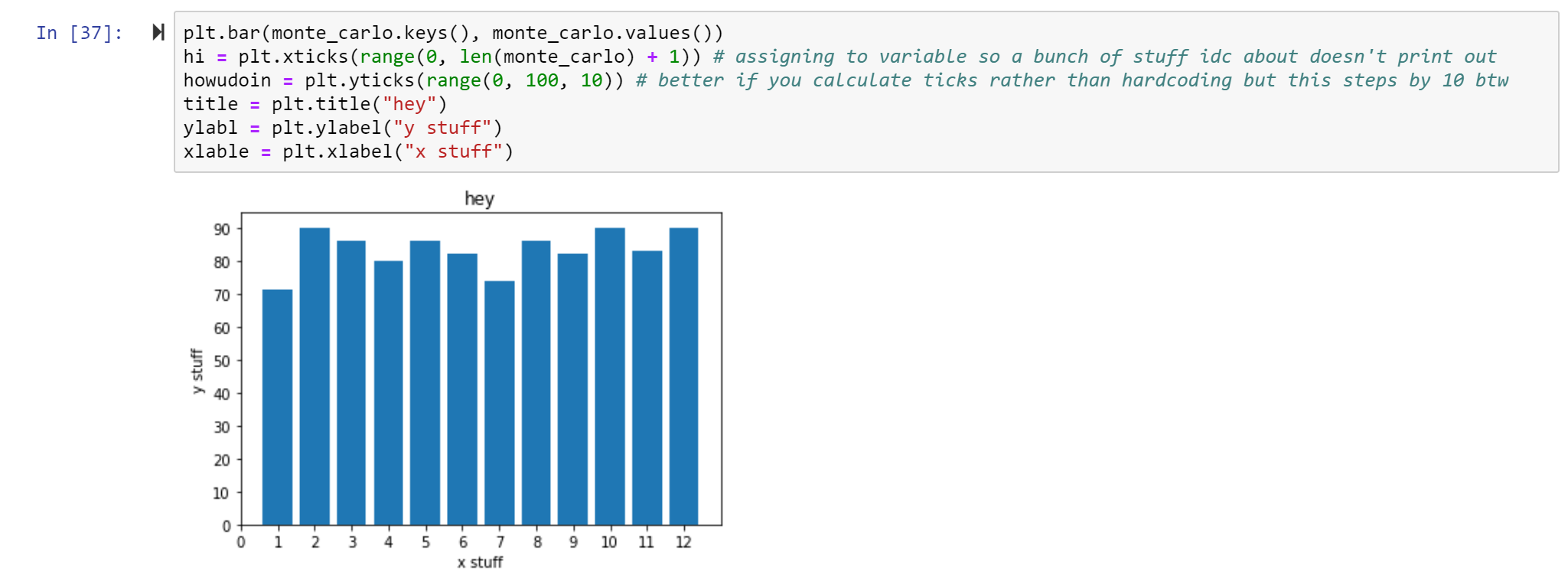
Using the library matplotlib we can create a bar chart to better understand the frequencies of each side of the di. Which key did we see rolled the most? The least?
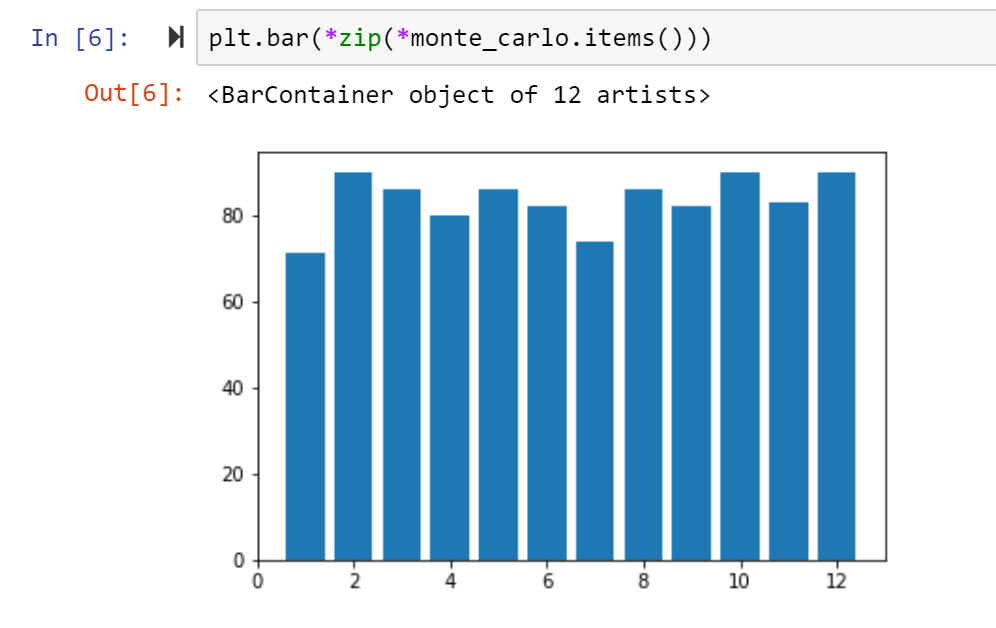
You may agree this graph is kind of weak. First, it’s missing a title and axis labels. We can also probably scale it a little better such that the highest bar is still under a ytick. And add all the keys, not just the even keys.
So… why isn’t random data biased?
Say the computer is on it’s first roll. Say the roll is a 2. Then it will roll again. The next roll doesn’t care whether the previous roll was a 2 or a 3. It will be whatever it is.
Random data is not biased because it does not discriminate. It cannot neglect any certain population. In the di example, there are 12 choices and they all have an equal probability of occurrence.
In fact, if I roll the di 1000 times, this will be more true than if I were to roll the di 10 times. A million would be even better. In fact, the larger the sample size, the more accurate the mean value reflects the population (plus other great stuff).
Randomly generated data, especially with a sufficiently large sample size, is not biased.
The only way this data would be biased is if the person rolling the di didn’t record all the 3’s because they hated the number 3. Or if the computer was told to ignore 10.
If di == 10 continue else monte_carlo[di] += 1
By the way, continue is a useful word to use if you’re in a for loop and have a condition where you don’t want the loop to do anything, to just skip to the next iteration.
So, use public datasets all you want. Just remember: random data can't lie.

One thought on “How to Find (Good) Data”